

Azure SQL Database – Hyperscale – jetzt im Public Preview
This post might contain affiliate links. We may earn a commission if you click and make a purchase. Your support is appreciated!
Auf der #MSIgnite wurde ein neues Feature bzw eine neue Variante von Azure SQL Database vorgestellt : Hyperscale!
Mit diesem neuen Produkt bietet Microsoft seinen Kunden eine Datenbank-Engine, welche schneller und flexibler auf plötzliche Daten-Wachstumsraten reagieren kann als die bisherigen. Mit Hyperscale kommen bisher bei on-premise SQL Servern unbekannte Technologien zum Einsatz, da diese sich erst realisieren ließen durch die Cloud-typische Trennung von Services, Netzwerk und Storage. Durch eben diese Trennung können neue Ansätz realisiert werden, welche – wie bei Azure SQLDB Hyperscale – neue Prozessstrukturen ermöglichen, hier wird nicht direkt in das Transaction-Log in einem Storage geschrieben, sondern erst einmal in einen Log-Services ähnlichem einer Queue im Servicebus. Dieser LogService übernimmt dann sozusagen die Verteilung der Daten in Richtung Storage, Secondary ComputeNodes und Page Servers.
Der Log-Service – Drehscheibe
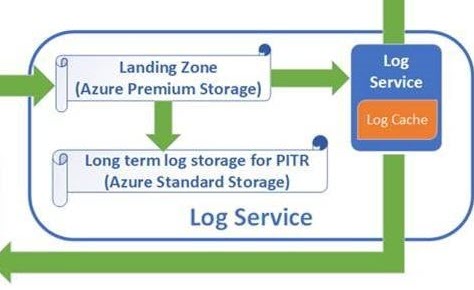
Der Log Service kümmert sich um die Datensicherheit, er ist dafür verantwortlich, dass die Daten sowohl für die Log-Sicherung also das Point-in-Time-Restore zur Verfügung stehen, als auch für die weitere Speicherung in den Compute Nodes sowie den Page Servern, aber wie im Detail…
Der Dateneingang auf dem Primary ComputeNode speichert jegliche Daten erst einmal auf einem Azure Premium Storage Device (welches schon dem Log-Service unterliegt), somit ist eine schnelle und sichere Speicherung der Daten sichergestellt. Der Log-Service nimmt diese Daten und verteilt sie dann an die Logsicherung (LTR & PiTR) und die weiteren ComputeNodes (some kind of LogShipping) und eben auch an die PageServer, welche die eigentliche Datenspeicherung übernehmen.
Der Datenspeicher – Page Server

Die Page Server übernehmen die Daten vom Log-Service um diese dann über spezielle Caching-Speicher auf lokale SSD-Platte zu speichern bzw später dann auf dem „normalen“ Azure Storage endgültig zu persitieren. Die PageServer sind im Grunde nichts anderes als die alt bekannten Datafiles auf einem on-premise SQL Server, denn auch die Datenbereitstellung in einer Hyperscale-Umgebung erfolgt über diese Page-Server, diese speichern nicht nur die Daten sondern stellen sie auch wieder zur Verfügung. Im Falle eines plötzlichen Datenwachstums können diese Page-Server sehr schnell und effizient skaliert werden, so dass zügig ein Vielfaches an Speicherplatz zur Verfügung gestellt werden kann.
Fazit – Azure SQL Database Hyperscale
Die Kombination und Trennung der einzelnen Funktionen machen einen sehr performanten Eindruck und lassen hoffen, dass sich diese Produkt am Markt etabliert. Auf jeden Fall ermöglicht es endlich Datenspeicherungen in der Cloud von mehr als 4-8 TB, welche bisher bei AzureSQLDB als Grenze galten. Manche Kunden bzw Solutions kommen eben leider nicht mit diesem „geringen“ Datenmengen aus… aber gerade die Trennung der Funktionen ermöglichen ein schnelles und flexibles Skalieren der Lösung, ob im Storage-Bereich oder bei den eigentlichen Compute-Nodes. So kann man mittels Hyperscale sehr flexibel und schnell auf wechselnde Anforderungen reagieren und entsprechend seine Datenbank-Umgebung anpassen und auch nur im Ansatz an Performance zu verlieren, da alle Funktionen von einander getrennt sind. Man kann die Speicherkapazitäten ohne Downtime variabel gestalten aber auch die Read-Compute-Nodes in Menge oder Größe varieren, so dass man z.B. auf einen Käuferansturm (mehr Lese-Operationen) schnell reagieren kann.
Mehr Informationen zu diesem neuen Public Preview und der Roadmap findet ihr wie immer im Microsoft Blog und den Dokumentationen.
https://azure.microsoft.com/en-us/blog/tag/azure-sql-database/
Dokumentation – Azure SQL Database
Beitragsfoto von Jon Tyson über Unsplash
This post might contain affiliate links. We may earn a commission if you click and make a purchase. Your support is appreciated!
Björn arbeitet auch weiterhin aus Griechenland als Senior Consultant – Microsoft Data Platform und Cloud für die Kramer&Crew in Köln. Auch der Community bleibt er aus der neuen Heimat treu, er engagiert sich auf Data Saturdays oder in unterschiedlichen Foren. Er interessiert sich neben den Themen rund um den SQL Server, Powershell und Azure SQL für Science-Fiction, Backen 😉 und Radfahren.
Amazon.com Empfehlungen
Damit ich auch meine Kosten für den Blog ein wenig senken kann, verwende ich auf diese Seite das Amazon.com Affiliate Programm, so bekomme ich - falls ihr ein Produkt über meinen Link kauft, eine kleine Provision (ohne zusätzliche Kosten für euch!).
Auto Amazon Links: Keine Produkte gefunden.
